
Veri Madenciliği Final Deneme Sınavı -10
Auzef Veri Madenciliği Final Soruları Deneme Sınavı -10
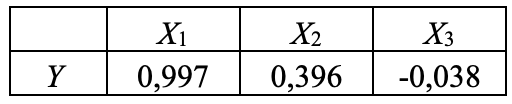
#1. Aşağıdaki tabloda bir veri setinde değişkenler arasındaki korelasyon katsayıları verilmiştir. Buna göre ifadelerden hangileri doğrudur? – I. Y değişkeni ile X1 arasında güçlü bir ilişki vardır. – II. Y değişkeni ile X2 arasında doğrusal bir ilişki yoktur. – III. Y değişkeni ile X3 arasında negatif yönlü bir ilişki vardır. – IV. X1 ve X2 arasında güçlü bir pozitif ilişki bulunmaktadır. – V. X2 değişkeni ile X3 arasında negatif bir ilişki vardır.
Cevap: C) I-III
Açıklama: Y değişkeni ile X1 arasında güçlü bir pozitif ilişki (0,997) ve Y değişkeni ile X3 arasında zayıf bir negatif ilişki (-0,038) vardır. X1 ve X2 arasında doğrudan bir korelasyon katsayısı verilmemiştir.
#2. Nesnelerin birden fazla kümeye ait olabileceği kümeleme türü hangisidir?
Cevap: E) Örtüşen Kümeleme
Açıklama: Örtüşen kümeleme, nesnelerin birden fazla kümeye ait olabileceği kümeleme türüdür. Bu sayede veri noktaları birden fazla kümeye dahil olabilir.
#3. Katmanlı (stratified) örnekleme hangi durumda kullanılır?
Cevap: A) Tüm nesne tiplerini yeterince temsil etmeyen durumlarda
Açıklama: Katmanlı örnekleme, tüm nesne tiplerinin yeterince temsil edilmediği durumlarda kullanılır, böylece her bir kategoriye ait veri temsil edilir.
#4. Doğrusal regresyonun ikili sonuçlar için uygun olmamasının nedeni nedir?
Cevap: A) İkili sonuçların doğrusal olmayan doğasını göz ardı etmesi
Açıklama: Doğrusal regresyon, ikili sonuçların doğrusal olmayan doğasını göz ardı eder, bu yüzden bu tür veriler için lojistik regresyon daha uygundur.
#5. Logit dönüşümü, lojistik regresyon modelinde hangi olasılık değerini daha doğrusal ve düzgün bir şekilde modellemeyi sağlar?
Cevap: A) Olasılıklar oranını (odds ratio)
Açıklama: Logit dönüşümü, olasılıklar oranını (odds ratio) daha doğrusal ve düzgün bir şekilde modellemeyi sağlar.
Öğrenci Dostu Öğrenme Yönetim Sistemi Lolonolo, bol bol test yapmayı önerir.
#6. Hangisi Logaritmik dönüşüm yapılma gerekçesi değildir?
Cevap: D) Veri normal dağılıma sahip olduğu için
Açıklama: Logaritmik dönüşüm genellikle verileri normal dağılıma yaklaştırmak için yapılır, bu nedenle veri zaten normal dağılıma sahipse bu dönüşüm gerekli değildir.
#7. Hangi yaklaşım özniteliklerin, veri madenciliği algoritması çalıştırılmadan önce, veri madenciliği görevinden bağımsız bir şekilde seçilmesini benimser?
Cevap: A) Filtre yaklaşım
Açıklama: Filtre yaklaşım, özniteliklerin veri madenciliği görevinden bağımsız olarak seçilmesini benimser ve bu sayede daha genel ve esnek bir seçim süreci sağlar.
#8. Lojistik regresyon, hangi tür veri setleri üzerinde çalışmaya daha uygundur?
Cevap: D) Kategorik ve ikili sonuçlar
Açıklama: Lojistik regresyon, özellikle kategorik ve ikili (binary) sonuçlar için uygundur, bu nedenle sınıflandırma problemlerinde yaygın olarak kullanılır.
#9. Ağaç yapısında alt kümeler oluşturan kümeleme türü hangisidir?
Cevap: C) Hiyerarşik Kümeleme
Açıklama: Hiyerarşik kümeleme, veriyi ağaç yapısında alt kümelere böler ve bu sayede farklı seviyelerdeki alt kümeler oluşturur.
#10. DBSCAN algoritmasında kullanılan epsilon (ε) nedir?
Cevap: B) Yoğunluk eşiği
Açıklama: Epsilon (ε), DBSCAN algoritmasında yoğunluk eşiği olarak kullanılır ve bir veri noktasının komşuluğunu belirler.
Öğrenci Dostu Öğrenme Yönetim Sistemi Lolonolo, bol bol test yapmayı önerir.
#11. K-ortalamalar kümeleme yönteminde, veri noktalarının kümelere atanmasında hangi kritere göre karar verilir?
Cevap: B) Küme merkezine olan uzaklığa göre
Açıklama: K-ortalamalar kümeleme yönteminde, veri noktalarının kümelere atanmasında küme merkezine olan uzaklığa göre karar verilir.
#12. Bir veri madenciliği analizi için ihtiyacımız olan tüm verileri toplamak ve işlemek için yeterli zamanımız olmadığında, örneklem büyüklüğü nasıl belirlenir?
Cevap: C) Uyarlanabilir örneklemeyle
Açıklama: Uyarlanabilir örnekleme, sınırlı zaman ve kaynaklarla veri toplama ve işleme işlemini optimize etmek için kullanılır.
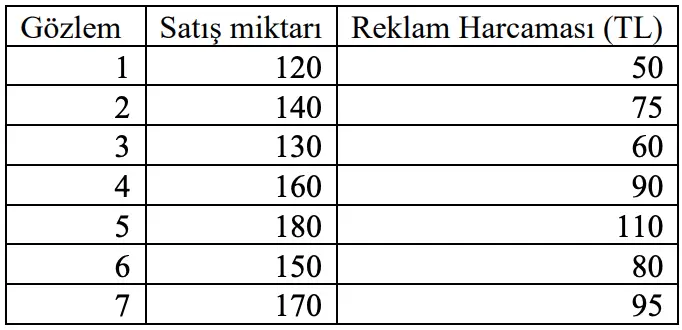
#13. Reklam için harcanan miktara bağlı olarak bir ürünün satışlarını tahmin etmek istediğimizi varsayalım. – 200’lük bir satış miktarı elde etmek için kaç TL harcanmalıdır?
Cevap: C) 128
Açıklama: Regresyon denklemi Y = 66,86 1,04X olduğuna göre, 200 = 66,86 1,04X denklemini çözerek X’i buluruz: X ≈ 128 TL olacaktır.
#14. Regresyon analizinde kullanılan en küçük kareler yöntemi neyi amaçlar?
Cevap: B) Gerçek ve tahmin edilen değerler arasındaki farkı en aza indirmeyi
Açıklama: En küçük kareler yöntemi, tahmin edilen değerler ile gerçek değerler arasındaki farkların karelerinin toplamını en aza indirmeyi amaçlar.
#15. Reklam için harcanan miktara bağlı olarak bir ürünün satışlarını tahmin etmek istediğimizi varsayalım. – Bağımsız değişkenin katsayısı (b) kaçtır?
Cevap: B) 1,04
Açıklama: Bağımsız değişkenin katsayısı (b), bağımsız değişkendeki bir birimlik artışın bağımlı değişkende 1,04 birimlik bir artışa neden olduğunu gösterir.
Öğrenci Dostu Öğrenme Yönetim Sistemi Lolonolo, bol bol test yapmayı önerir.
#16. SOM’un (Kendi Kendini Düzenleyen Haritalar) eğitim süreci nasıl işler?
Cevap: B) Rekabetçi öğrenme kullanarak ağırlıkları günceller.
Açıklama: SOM’un eğitim süreci, rekabetçi öğrenme kullanarak ağırlıkları günceller ve verileri düşük boyutlu bir haritaya projekte eder.
#17. Bir regresyon modelinde bağımlı değişken ile bir bağımsız değişken arasında bulunan katsayı (b) 2, sabit terim (a) ise 5 olarak bulunmuştur. Bu durumda, bağımlı değişkenin değeri 4 olduğunda tahmini sonuç ne olur?
Cevap: B) 13
Açıklama: Regresyon denklemi Y = a bX olduğuna göre, Y = 5 2(4) = 13 olacaktır.
#18. Z-Skor Normalizasyonu nedir?
Cevap: D) Değerleri ortalaması 0 ve standart sapması 1 olacak şekilde dönüştürme
Açıklama: Z-skor normalizasyonu, verileri ortalaması 0 ve standart sapması 1 olacak şekilde dönüştürerek, farklı ölçeklerdeki verilerin karşılaştırılmasını kolaylaştırır.
#19. Sigmoid fonksiyonunun temel özelliklerinden biri nedir?
Cevap: B) Herhangi bir gerçel sayıyı 0 ile 1 arasında bir değere dönüştürür
Açıklama: Sigmoid fonksiyonu, giriş değerini 0 ile 1 arasında bir olasılık değerine dönüştürür, bu nedenle lojistik regresyon modellerinde kullanılır.
#20. Öznitelik ayrıklaştırması aşağıdakilerden hangisini içerir?
Cevap: B) Sürekli bir değişkenin kategorik bir değişkene dönüştürülmesi
Açıklama: Öznitelik ayrıklaştırması, sürekli bir değişkenin belirli aralıklara veya kategorilere dönüştürülmesini içerir.
Öğrenci Dostu Öğrenme Yönetim Sistemi Lolonolo, bol bol test yapmayı önerir.
SONUÇ
İstanbul Üniversitesi Açık ve Uzaktan Eğitim Fakültesi (Auzef)
Açık Öğretim Fakültesi
Bölüm : Yönetim Bilişim Sistemleri Lisans
4. Sınıf Veri Madenciliği Bahar Dönemi
Auzef Veri Madenciliği Final Soruları Deneme Sınavı -10
İstanbul Üniversitesi Açık ve Uzaktan Eğitim Fakültesi (Auzef)
Açık Öğretim Fakültesi
Bölüm : Yönetim Bilişim Sistemleri Lisans
4. Sınıf Veri Madenciliği Bahar Dönemi
Auzef Veri Madenciliği Final Soruları Deneme Sınavı -10



HD Quiz powered by harmonic design
Auzef Veri Madenciliği Final Soruları Deneme Sınavı -10
| İstanbul Üniversitesi Açık ve Uzaktan Eğitim Fakültesi (Auzef) Açık Öğretim Fakültesi Bölüm : Yönetim Bilişim Sistemleri Lisans 4. Sınıf Veri Madenciliği Bahar Dönemi Auzef Veri Madenciliği Final Soruları Deneme Sınavı -10 |
|---|
Auzef Veri Madenciliği Final Soruları Deneme Sınavı -10
|
Auzef Veri Madenciliği Final Soruları Deneme Sınavı -10
|
Auzef Veri Madenciliği Final Soruları Deneme Sınavı -10
|


Yönetim Bilişim Sistemleri Lisans
Auzef Yönetim Bilişim Sistemleri Lisans 4. Sınıf Bahar Dönemi Final Soruları ve Deneme Sınavları, 2024 Sınav Soruları