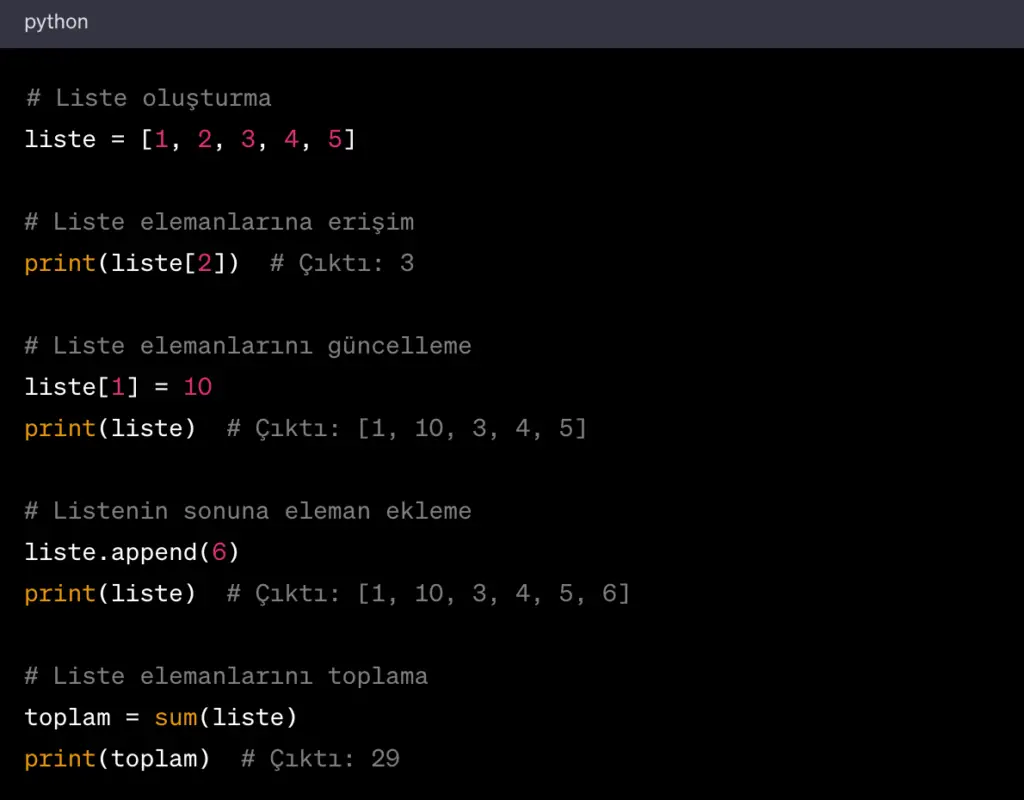
1. Yukarıda verilen Python kodunun ekran çıktısının sonucu aşağıdakilerden hangisidir?
A) 1, 2, 3, 4
B) 2, 4, 6, 8, 10
C) 6, 7, 8, 9
D) 6, 7, 8, 9, 10
E) 1, 3, 5, 7, 9
Cevap : A) 1, 2, 3, 4

Kodun çıktısı: 1, 2, 3, 4
Açıklama : Kod, 1’den başlayarak 10’a kadar olan sayılar üzerinde iterasyon yapar. i değeri 5’e eşit olduğunda döngü sona erer. print(i) komutu döngünün dışında olduğu için 1, 2, 3 ve 4 değerleri yazdırılı
|

2. Yukarıdaki Python kodunun vereceği sonuç aşağıdakilerden hangisidir?
A) 5
B) 0
C) 2
D) 1
E) 3
Cevap : D) 1

Kodun çıktısı: 1
Açıklama : Sözlükte d[‘a’] 0, d[‘b’] 1 ve d[‘c’] 5 değerlerine sahiptir. İlk koşulda d[‘a’] 0 olduğundan if bloğu çalışmaz, d[‘b’] 1 olduğundan elif bloğu çalışır ve 1 yazdırılır.
|
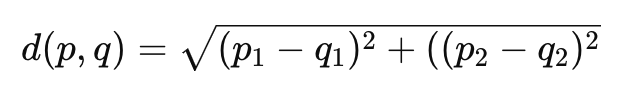
3. Yukarıda verilen denklem K-means kümeleme algoritmasında ne amaçla kullanılır?
A) Veriler ile veri merkezleri arasındaki mesafeyi hesaplamak için
B) Veri uzunluklarını hesaplamak için
C) Küme elemanlarının sayısını kontrol etmek için
D) Veri merkezlerini hesaplamak için
E) Küme sayılarını belirlemek için
Cevap : A) Veriler ile veri merkezleri arasındaki mesafeyi hesaplamak için
Açıklama : Bu denklem, Euclidean mesafesini hesaplamak için kullanılır ve K-Means kümeleme algoritmasında, veriler ile küme merkezleri arasındaki mesafeyi hesaplamak için kullanılır. Algoritmanın amacı, her bir veri noktasını en yakın küme merkezine atamaktır.
|
4. Bir arabanın satış fiyatı (1.000 $) ile yaşı (yıl olarak) arasındaki ilişki, belirli bir modeldeki rastgele araba örneklerinden tahmin edilerek aşağıdaki ilişki formülü elde edilmiştir.
satışücreti=24.2-(1.182)yıl
Bu denklemden aşağıdaki ifadelerden hangisi çıkarılabilir?
A) Otomobil her yıl yaşlandığında satış fiyatı yaklaşık 2420 $ düşer.
B) Yeni bir arabanın maliyeti yaklaşık 23.018 $ olur.
C) Yeni bir arabanın maliyeti yaklaşık 11.820 $ olur.
D) Otomobil her yıl yaşlandığında satış fiyatı yaklaşık %11,82 düşer.
E) Otomobil her yıl yaşlandığında satış fiyatı yaklaşık 1182 $ düşer.
Cevap : E) Otomobil her yıl yaşlandığında satış fiyatı yaklaşık 1182 $ düşer.
Açıklama : Denklemde yıl parametresi her yıl için 1.182 düşüş gösterir. Bu, her yıl için 1182 dolarlık bir düşüş anlamına gelir
|
5. Bilgisayarın “C” ana dizinin altında yer alan “VERI” adlı dizinden “iller” adlı ve “csv” uzantılı dosyayı okumak için yazılması gereken Python komut satırı aşağıdakilerden hangisidir?
A) iller=pd.read_csv(C:/VERI/iller.csv)
B) iller=pd.read.csv(“C:/VERI/iller.csv”)
C) iller=pd.read_csv(“C:/VERI/iller.csv”)
D) iller=read_csv(“C:/VERI/iller.csv”)
E) iller=pd.read_csv(“C:/VERI/iller_csv”)
Cevap : C) iller=pd.read_csv(“C:/VERI/iller.csv”)
Açıklama : CSV dosyasını pandas ile okumak için doğru komut pd.read_csv() fonksiyonudur.
|
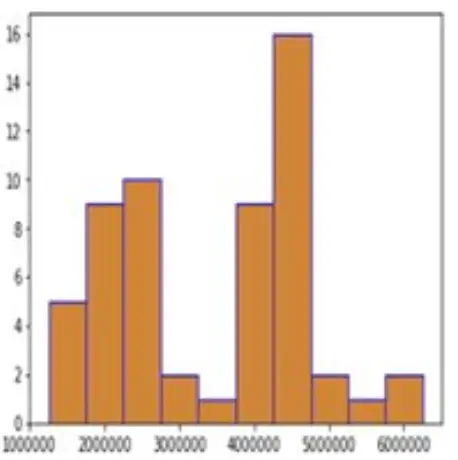
6. Python kütüphanesi ile oluşturulan yukarıdaki grafikte, grafik kenarlarının farklı renkte olmasını sağlayan parametre/argüman aşağıdakilerden hangisidir?
A) color=
B) linecolor=
C) barcolor=
D) edgecolor=
E) facecolor=
Cevap : D) edgecolor=
Açıklama : Python’da matplotlib kütüphanesi ile grafik oluştururken, barların kenar renklerini ayarlamak için ‘edgecolor’ parametresi kullanılır. Bu parametre, her bir barın kenar çizgilerinin rengini belirler.
|
7. Lojistik regrasyon modeli tahmin işleminde aşağıdaki yaklaşımlardan hangisini kullanır?
A) Negatif binom dağılım yaklaşımı
B) Sıradan en küçük kareler (OLS) yaklaşımı
C) Maksimum olasılık tahmini (MLS) yaklaşımı
D) Poisson dağılım yaklaşımı
E) Üstel tahmin dağılım yaklaşımı
Cevap : C) Maksimum olasılık tahmini (MLS) yaklaşımı
Açıklama : Lojistik regresyon, bağımlı değişkenin kategorik olduğu durumlarda kullanılan bir regresyon analizidir. Tahmin işleminde, parametrelerin en iyi tahminlerini elde etmek için Maksimum Olasılık Tahmini (Maximum Likelihood Estimation, MLE) kullanılır. Bu yöntem, verilen veri seti için modelin parametrelerinin olasılığını en yüksek hale getirecek şekilde ayarlanmasını sağlar.
Bu nedenle, lojistik regresyon modelinde tahmin işlemi için Maksimum Olasılık Tahmini (MLS) yaklaşımı kullanılır. |
8
1. plt.legend()
2. x = np.linspace(1, 10, 20)
3. plt.show()
4. plt.xlabel(‘X-Etiket’)
5. plt.plot(x, label=’Örnek Çizim’)
Yukarıda numaralandırılmış kodlar ile çizim oluşturmak ve görüntülemek için verilen komutlar hangi sırayla çalıştırılmalıdır?
A) 5-4-1-3-2
B) 2-4-5-1-3
C) 1-2-4-3-5
D) 4-2-1-3-5
E) 2-5-4-1-3
Cevap : E) 2-5-4-1-3
Açıklama : Bu komutlar, matplotlib kullanarak bir çizim oluşturmak ve görüntülemek için gereken adımları içerir. İşte doğru sıralama ve her adımın ne yaptığı:
1- x = np.linspace(1, 10, 20): x ekseni için 1 ile 10 arasında 20 eşit aralıkta değerler oluşturur.
2- plt.plot(x, label=’Örnek Çizim’): x eksenindeki değerleri y eksenine çizer ve etiketi ‘Örnek Çizim’ olarak belirler.
3- plt.xlabel(‘X-Etiket’): x eksenine ‘X-Etiket’ yazısını ekler.
4- plt.legend(): Çizimdeki etiketleri gösterir.
5- plt.show(): Çizimi ekranda gösterir.
Bu adımlar doğru sırayla yapıldığında, matplotlib ile düzgün bir çizim oluşturulur ve ekranda görüntülenir. |
9. Aşağıdaki bilişim firmalarından hangisi Python dilini resmî programlama dili olarak kabul etmiştir?
A) Microsoft
B) Google
C) Apple
D) Amazon
E) IBM
Cevap : B) Google
Açıklama : Google, Python’u resmi programlama dillerinden biri olarak kabul eden ve geniş ölçüde kullanan firmalardan biridir. Google, Python’u çeşitli projelerinde ve ürünlerinde yoğun bir şekilde kullanmaktadır. Python’un sadeliği ve çok yönlülüğü, Google’ın bu dili benimsemesinde önemli bir rol oynamıştır. Bu nedenle, Python’un resmi olarak kabul edildiği firmalardan biri Google’dır.
|
10. Algoritma kavramı ile ilgili aşağıda verilen ifadelerden hangisi doğrudur?
A) Matematiksel işlemleri tanımlayan harfler ve sayılar topluluğudur.
B) Girdi olarak bir değer alan ve girdiye bağlı olarak çıktı değeri üreten bir hesaplama prosedürüdür.
C) Makine yapma bilimi, insanlar tarafından yapıldığında zekâ gerektiren görevleri yerine getirir.
D) Matematiksel işlemler için kullanılan bir hesaplama tekniğidir.
E) Makine öğrenimi tekniklerini kullanır. Burada program,
Cevap: B) Girdi olarak bir değer alan ve girdiye bağlı olarak çıktı değeri üreten bir hesaplama prosedürüdür.
Açıklama : Algoritma, belirli bir problemi çözmek veya belirli bir görevi yerine getirmek için tanımlanmış adım adım talimatlar dizisidir. Bu talimatlar, girdileri alır ve bu girdilere dayalı olarak belirli bir çıktıyı üretir. Algoritmalar, bilgisayar biliminin temel kavramlarından biridir ve çeşitli programlama ve problem çözme senaryolarında kullanılır.
|
|
11
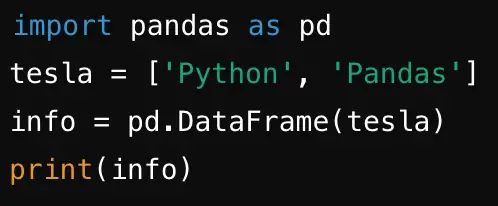
.  Yukarıda verilen “tesla” adlı liste veri yapısını “info” adlı veri çerçevesine dönüştürmek için “?” yerine yazılması gereken kod aşağıdakilerden hangisidir?
A) info=pd.DataFrame(tesla)
B) info=DataFrame(tesla)
C) info=Datalist(tesla)
D) info=pd.listFrame(tesla)
E) info=list_DataFrame(tesla)
Cevap : A) info=pd.DataFrame(tesla)
Açıklama : Pandas kütüphanesinde bir listeyi veri çerçevesine dönüştürmek için pd.DataFrame() fonksiyonu kullanılır. Bu fonksiyon, listeyi bir veri çerçevesi (DataFrame) nesnesine dönüştürür. Doğru kod aşağıdaki gibidir:
|
12. Aşağıda Python dilinde oluşturulan ve adı “data” olan veri çerçevesi verilmiştir.
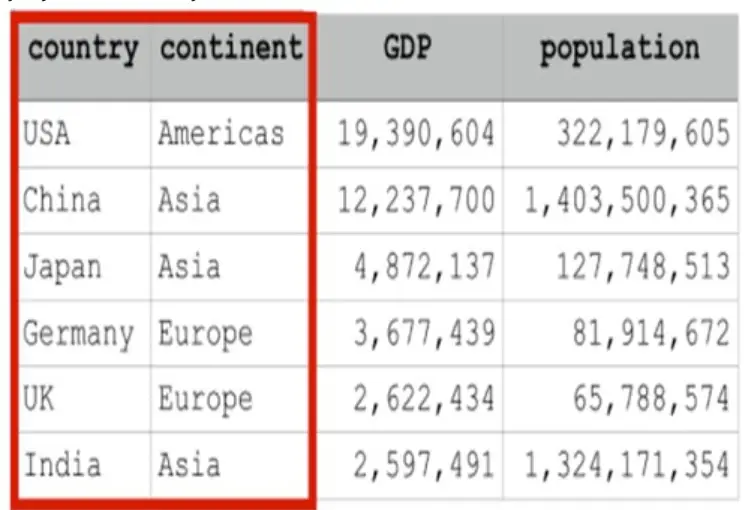
Bu veri çerçevesinde kalın çizgilerle çevrelenmiş kayıtları görüntüleyen kod aşağıdakilerden hangisidir?
A) data.iloc[:,0:5]
B) data.iloc[:,1:3]
C) data.iloc[:,0:3]
D) data.iloc[:,0:2]
E) data.iloc[:,1:2]
Cevap : D) data.iloc[:,0:2]
Açıklama : Kalın çizgilerle çevrelenmiş kayıtlar “country” ve “continent” sütunlarını içerir. data.iloc[:,0:2] kodu, veri çerçevesindeki 0. sütundan (country) başlayarak 2. sütuna (continent) kadar olan sütunları seçer.

Bu kod, belirtilen sütunları görüntüleyecektir. |
13. Python’da oluşturulan ogr=[“Ahmet”, “Işıl”, “Mehmet”, “Ayşe”, “Kazım”, “Zehra”, “Turgay”] adlı listeye; “Zarife” adlı öğrenciyi ekleyecek söz dizimi (komut satırı) hangi seçenekte doğru olarak verilmiştir?

A) ogr.append[“Zarife”]
B) ogr.add(“Zarife”)
C) ogr.append(“Zarife”)
D) ogr.add[“Zarife”]
E) ogr.append(Zarife)
Cevap : C) ogr.append(“Zarife”)
Açıklama : Python’da bir listeye yeni bir eleman eklemek için append() metodu kullanılır. Bu metot, listeye eleman eklemek için en yaygın kullanılan yöntemdir ve doğru şekilde kullanımı parantez içinde eklenen elemanla birlikte olmalıdır.
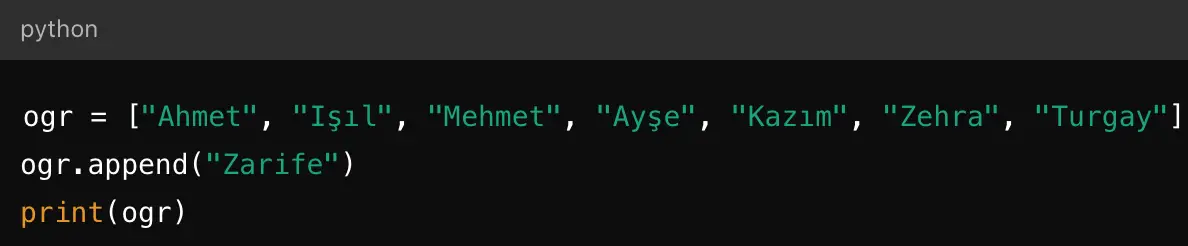
Bu kod çalıştırıldığında, “Zarife” adlı öğrenci listeye eklenecektir ve çıktı şu şekilde olacaktır:

|
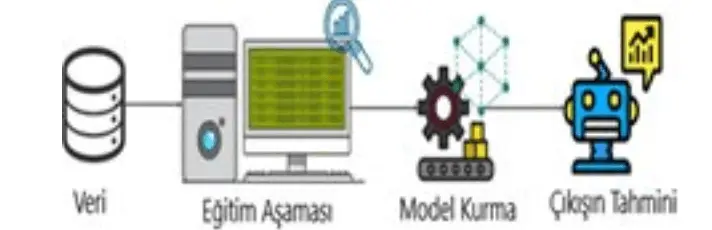
14. Yukarıda verilen görseli en doğru şekilde tanımlayan seçenek aşağıdakilerden hangisidir?
A) Keşifsel veri analizini temsil eder.
B) Makine öğrenimini temsil eder.
C) Python programlama sürecini tanımlar.
D) Algoritmanın çalışmasını açıklar.
E) Grafik çizim sürecini temsil eder.
Cevap : B) Makine öğrenimini temsil eder.
Açıklama : Görsel, makine öğrenimi sürecinin adımlarını temsil etmektedir. Bu adımlar genellikle veri toplama, veriyi işleme (eğitim aşaması), model oluşturma ve sonuçları tahmin etme şeklinde ilerler. Görselde bu aşamalar açıkça gösterilmektedir: “Veri”, “Eğitim Aşaması”, “Model Kurma” ve “Çıkışın Tahmini”.
Bu nedenle, görsel makine öğrenimini en doğru şekilde temsil etmektedir. |
| 15. Gruplandırılmış bir verinin dağılımının en iyi temsilini ve her bir veri değerinin sıklığını gösteren grafik türü aşağıdakilerden hangisidir?
A) Çubuk grafiği
B) Pasta dilimi grafiği
C) Bar grafiği
D) Histogram grafiği
E) Scatter grafiği
Cevap : D) Histogram grafiği
Açıklama : Histogram grafiği, verinin gruplandırılmış dağılımını ve her bir grup için veri değerlerinin sıklığını gösteren bir grafik türüdür. Histogramlar, sürekli veri dağılımlarını görselleştirmek için kullanılır ve veri değerlerinin belirli aralıklarda (binler) nasıl dağıldığını gösterir. Bu grafikte, x ekseni veri aralıklarını, y ekseni ise bu aralıklardaki veri değerlerinin sıklığını temsil eder.Bu nedenle, gruplandırılmış bir verinin dağılımını ve sıklığını en iyi şekilde temsil eden grafik türü histogram grafiğidir.
|
16. Aşağıdaki ifadelerden hangisi en küçük kareler yönteminin amacını en iyi şekilde açıklamaktadır?
A) Ölçüm sonucu elde edilmiş veri noktalar arasındaki mesafeyi en aza indirmeyi sağlar.
B) Hata kalıntıların toplamının en küçük değerini bize sağlayan kesişim ve eğimin (en iyi) değerlerini bulur.
C) Ölçüm sonucu bulunan noktalardan geçecek doğrunun sadece eğimini bulmayı sağlar.
D) Ölçüm sonucu bulunan noktalara mümkün olduğunca en uzak geçecek bir çizgi bulmayı sağlar.
E) Ölçüm sonucu elde edilmiş veri noktalarına mümkün olduğu kadar yakın geçecek bir fonksiyon eğrisi bulmaya yarar.
Cevap : E) Ölçüm sonucu elde edilmiş veri noktalarına mümkün olduğu kadar yakın geçecek bir fonksiyon eğrisi bulmaya yarar.
Açıklama : ?
|
17.
Python’da K-means kütüphanesini çağırmak için çalışma sayfasına yazılması gereken kod aşağıdakilerden hangisidir?
A) from pandas.cluster import K-Means
B) from sklearn.cluster import K-cluster
C) from numpy.cluster import K-Means
D) from mutplolib.cluster import K-Means
E) from sklearn.cluster import K-Means
Cevap : E) from sklearn.cluster import K-Means
Açıklama : Python’da K-means kümeleme algoritmasını kullanmak için scikit-learn (sklearn) kütüphanesinden KMeans sınıfı import edilir. Doğru import ifadesi şu şekildedir:
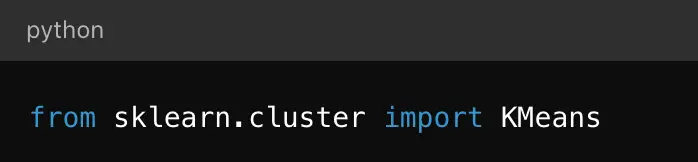
Bu kod, sklearn kütüphanesinin cluster modülünden KMeans sınıfını çağırır ve K-means algoritmasını kullanmanıza olanak tanır.
|
| 18.
dizi= np.array([[1,2,3,4,5], [6,7,8,9,10]]) print(?)

Yukarıda verilen “dizi” adlı dizideki “8” sayısını ekrana yazdırmak için “print()” fonksiyonu içerisine yazılması gereken kodun söz dizimi aşağıdakilerden hangisidir?
A) print(dizi[7,2])
B) print(dizi[2,3])
C) print(dizi[1,2])
D) print(dizi[3,3])
E) print(dizi[3,0])
Cevap : C) print(dizi[1,2])
Açıklama : NumPy dizilerinde elemanlara erişim için köşeli parantezler kullanılır ve indeksler sıfırdan başlar. Verilen dizi iki boyutlu bir dizidir ve 8 sayısı ikinci satır ve üçüncü sütundadır. Bu nedenle, dizi[1,2] ifadesi doğru elemanı döndürecektir.
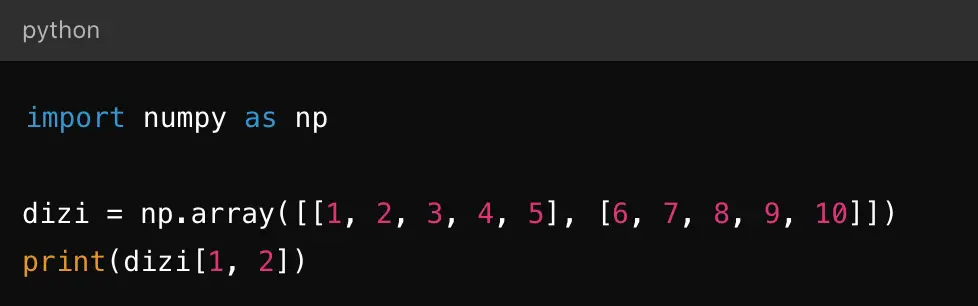
Bu kod çalıştırıldığında, çıktı olarak 8 sayısı ekrana yazdırılacaktır. |
19. Lojistik regresyon yöntemi aşağıdakilerden hangisini bulmak için kullanılır?
A) Sürekli tahmin edici değişkenler arasındaki doğrusal ilişki
B) Sürekli tahmin edici değişkenler ile sonuç değişkeninin logiti arasındaki doğrusal ilişki
C) Gözlemler arasındaki zıt ilişki
D) Gözlemler arasındaki doğrusal ilişki
E) Sürekli tahminî değişkenler ile sonuç değişkeni arasındaki doğrusal ilişki
Cevap : B) Sürekli tahmin edici değişkenler ile sonuç değişkeninin logiti arasındaki doğrusal ilişki
Lojistik regresyon, bağımlı değişkenin kategorik olduğu (örneğin, 0 veya 1 gibi ikili sonuçlar) durumlarda kullanılan bir regresyon analizidir. Bu yöntem, sürekli tahmin edici değişkenlerin (bağımsız değişkenler) sonuç değişkeninin logit (log odds) dönüşümü ile olan doğrusal ilişkisini bulmak için kullanılır.
Logit dönüşümü, bir olasılığı 0 ile 1 arasında sınırlamaya ve doğrusal bir modelle ilişkilendirmeye yarar. Lojistik regresyon modelinde, bağımsız değişkenlerin etkisi logit fonksiyonu aracılığıyla hesaplanır:
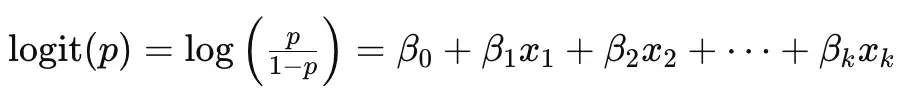
Burada p, bağımlı değişkenin 1 olma olasılığıdır. Bu denkleme göre, bağımsız değişkenlerin katsayıları (β değerleri), logit dönüşümü üzerinden bağımlı değişkene olan etkisini açıklar. Bu nedenle, lojistik regresyon, sürekli tahmin edici değişkenler ile sonuç değişkeninin logiti arasındaki doğrusal ilişkiyi belirlemek için kullanılır.
|
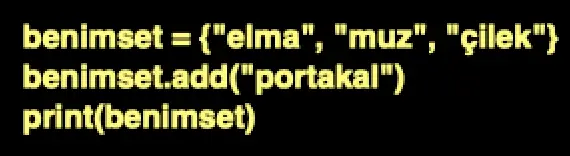
20. Yukarıda verilen Python programının çıktısı aşağıdakilerden hangisidir?
A) {elma, muz, çilek, portakal}
B) {elma, çilek, portakal}
C) {elma, muz, çilek}
D) {çilek, portakal}
E) {elma, muz, portakal}
Cevap : A) {elma, muz, çilek, portakal}
Açıklama : Set veri yapısına add() metodu ile “portakal” eklenir. Set, sıralanmamış bir koleksiyon olduğundan, elemanlar sırasız olarak yazdırılır.
|
|