
Veri Madenciliği Vize Deneme Sınavı -3
Veri Madenciliği Vize Deneme Sınavı -3
#1. Veri setindeki değerlerin yarısından fazlasını/ortasını belirten istatistik hangisidir?
Cevap: C) Medyan
Açıklama: Medyan, veri setindeki değerlerin ortasını belirten ve veri setini iki eşit parçaya bölen istatistiktir.
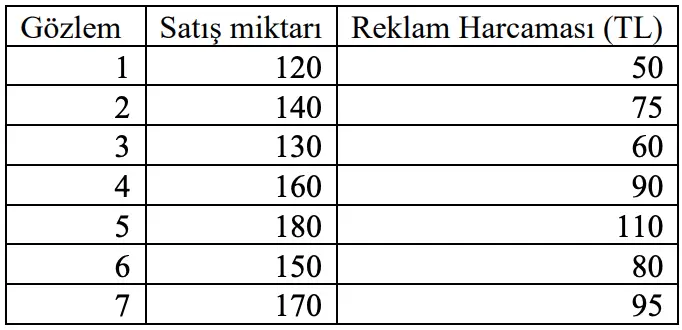
#2. Reklam için harcanan miktara bağlı olarak bir ürünün satışlarını tahmin etmek istediğimizi varsayalım. - 200'lük bir satış miktarı elde etmek için kaç TL harcanmalıdır?
Cevap: C) 128
Açıklama: Regresyon denklemi Y = 66,86 1,04X olduğuna göre, 200 = 66,86 1,04X denklemini çözerek X’i buluruz: X ≈ 128 TL olacaktır.
#3. Kategorik bir özniteliğin ikili hale getirilmesinde aşağıdakilerden hangileri yanlıştır? - I. Veri özelliği sıralı ise, atama yaparken sıralamayı korumak gerekir - II. Kategorik değerleri ikili formata dönüştürürken 0 ve 1'leri istenilen şekilde atanabilir - III. Kategori sayısı kadar sütun oluşturmak gerekir
Cevap: D) Yalnız III
Açıklama: Kategorik bir özniteliğin ikili hale getirilmesinde, kategori sayısı kadar sütun oluşturmak gerekmez. Bu işlem, genellikle bir sıcak kodlama (one-hot encoding) yöntemi ile gerçekleştirilir.
#4. Katmanlı (stratified) örnekleme hangi durumda kullanılır?
Cevap: A) Tüm nesne tiplerini yeterince temsil etmeyen durumlarda
Açıklama: Katmanlı örnekleme, tüm nesne tiplerinin yeterince temsil edilmediği durumlarda kullanılır, böylece her bir kategoriye ait veri temsil edilir.
#5. Öznitelik ayrıklaştırması aşağıdakilerden hangisini içerir?
Cevap: B) Sürekli bir değişkenin kategorik bir değişkene dönüştürülmesi
Açıklama: Öznitelik ayrıklaştırması, sürekli bir değişkenin belirli aralıklara veya kategorilere dönüştürülmesini içerir.
#6. Kutu grafiği hangi istatistikleri görsel olarak temsil eder?
Cevap: C) Çeyreklikler
Açıklama: Kutu grafiği, veri setindeki çeyreklikleri, medyanı ve olası aykırı değerleri görsel olarak temsil eder.
#7. Saçılım grafiği hangi tür ilişkileri görsel olarak göstermek için kullanılır?
Cevap: D) İki değişken arasındaki ilişkiler
Açıklama: Saçılım grafiği, iki değişken arasındaki ilişkileri ve bu ilişkinin yönünü ve gücünü görsel olarak göstermek için kullanılır.
#8. Bir veri madenciliği analizi için ihtiyacımız olan tüm verileri toplamak ve işlemek için yeterli zamanımız olmadığında, örneklem büyüklüğü nasıl belirlenir?
Cevap: C) Uyarlanabilir örneklemeyle
Açıklama: Uyarlanabilir örnekleme, sınırlı zaman ve kaynaklarla veri toplama ve işleme işlemini optimize etmek için kullanılır.
#9. Hangi durumda Basit Fonksiyonel Dönüşümler veya Normalizasyon kullanılabilir?
Cevap: C) Veri setinin analizde daha anlamlı ve doğrusal bir şekle getirilmesi için
Açıklama: Basit fonksiyonel dönüşümler ve normalizasyon, veri setini analizde daha anlamlı ve doğrusal bir şekle getirmek için kullanılır.
#10. Hangi yaklaşım özniteliklerin, veri madenciliği algoritması çalıştırılmadan önce, veri madenciliği görevinden bağımsız bir şekilde seçilmesini benimser?
Cevap: A) Filtre yaklaşım
Açıklama: Filtre yaklaşım, özniteliklerin veri madenciliği görevinden bağımsız olarak seçilmesini benimser ve bu sayede daha genel ve esnek bir seçim süreci sağlar.
#11. Bir regresyon modelinde bağımlı değişken ile bir bağımsız değişken arasında bulunan katsayı (b) 2, sabit terim (a) ise 5 olarak bulunmuştur. Bu durumda, bağımlı değişkenin değeri 4 olduğunda tahmini sonuç ne olur?
Cevap: B) 13
Açıklama: Regresyon denklemi Y = a bX olduğuna göre, Y = 5 2(4) = 13 olacaktır.
#12. Veri setindeki değerlerin ortalama etrafındaki yayılımı ölçen istatistik hangisidir?
Cevap: B) Varyans
Açıklama: Varyans, veri setindeki değerlerin ortalama etrafındaki yayılımını ölçer ve değerlerin ne kadar dağıldığını gösterir.
#13. Aşağıdakilerden hangisi birleştirme (aggregation) işleminin bir riskidir?
Cevap: C) Detaylardan bazılarının kaybolması
Açıklama: Birleştirme işlemi sırasında bazı detayların kaybolması riski vardır, bu da veri analizinde önemli bilgilere ulaşmayı zorlaştırabilir.
#14. Regresyon analizinde kullanılan en küçük kareler yöntemi neyi amaçlar?
Cevap: B) Gerçek ve tahmin edilen değerler arasındaki farkı en aza indirmeyi
Açıklama: En küçük kareler yöntemi, tahmin edilen değerler ile gerçek değerler arasındaki farkların karelerinin toplamını en aza indirmeyi amaçlar.
#15. Reklam için harcanan miktara bağlı olarak bir ürünün satışlarını tahmin etmek istediğimizi varsayalım. - Bağımsız değişkenin katsayısı (b) kaçtır?
Cevap: B) 1,04
Açıklama: Bağımsız değişkenin katsayısı (b), bağımsız değişkendeki bir birimlik artışın bağımlı değişkende 1,04 birimlik bir artışa neden olduğunu gösterir.
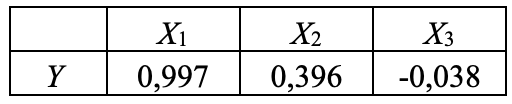
#16. Aşağıdaki tabloda bir veri setinde değişkenler arasındaki korelasyon katsayıları verilmiştir. Buna göre ifadelerden hangileri doğrudur? - I. Y değişkeni ile X1 arasında güçlü bir ilişki vardır. - II. Y değişkeni ile X2 arasında doğrusal bir ilişki yoktur. - III. Y değişkeni ile X3 arasında negatif yönlü bir ilişki vardır. - IV. X1 ve X2 arasında güçlü bir pozitif ilişki bulunmaktadır. - V. X2 değişkeni ile X3 arasında negatif bir ilişki vardır.
Cevap: C) I-III
Açıklama: Y değişkeni ile X1 arasında güçlü bir pozitif ilişki (0,997) ve Y değişkeni ile X3 arasında zayıf bir negatif ilişki (-0,038) vardır. X1 ve X2 arasında doğrudan bir korelasyon katsayısı verilmemiştir.
#17. Aşağıdaki yöntemlerden hangileri özellik oluşturma (feature creation) için kullanılabilir? - I. Öznitelik oluşturma - II. Veriyi yeni bir uzaya eşleme - III. Öznitelik inşası
Cevap: D) I-II-III
Açıklama: Öznitelik oluşturma, veriyi yeni bir uzaya eşleme ve öznitelik inşası, özellik oluşturma için kullanılan yöntemlerdir.
#18. Kök ve yaprak diyagramı hangi amaçla kullanılır?
Cevap: B) Sürekli verilerin dağılımını göstermek için
Açıklama: Kök ve yaprak diyagramı, sürekli verilerin dağılımını ve veri setindeki bireysel değerlerin frekansını görselleştirmek için kullanılır.
#19. Boyut azaltmanın avantajlarından hangisi doğrudur?
Cevap: B) Veri işleme sürelerini kısaltır
Açıklama: Boyut azaltma, veri işleme sürelerini kısaltarak analiz süreçlerini hızlandırır ve daha etkin hale getirir.
#20. Z-Skor Normalizasyonu nedir?
Cevap: D) Değerleri ortalaması 0 ve standart sapması 1 olacak şekilde dönüştürme
Açıklama: Z-skor normalizasyonu, verileri ortalaması 0 ve standart sapması 1 olacak şekilde dönüştürerek, farklı ölçeklerdeki verilerin karşılaştırılmasını kolaylaştırır.
SONUÇ
İstanbul Üniversitesi Açık ve Uzaktan Eğitim Fakültesi (Auzef)
Açık Öğretim Fakültesi
Bölüm : Yönetim Bilişim Sistemleri Lisans
4. Sınıf Veri Madenciliği Bahar Dönemi
Veri Madenciliği Vize Deneme Sınavı -3
İstanbul Üniversitesi Açık ve Uzaktan Eğitim Fakültesi (Auzef)
Açık Öğretim Fakültesi
Bölüm : Yönetim Bilişim Sistemleri Lisans
4. Sınıf Veri Madenciliği Bahar Dönemi
Veri Madenciliği Vize Deneme Sınavı -3



HD Quiz powered by harmonic design
Veri Madenciliği Vize Deneme Sınavı -3
| İstanbul Üniversitesi Açık ve Uzaktan Eğitim Fakültesi (Auzef) Açık Öğretim Fakültesi Bölüm : Yönetim Bilişim Sistemleri Lisans 4. Sınıf Veri Madenciliği Bahar Dönemi Veri Madenciliği Vize Deneme Sınavı -3 |
|---|
Veri Madenciliği Vize Deneme Sınavı -3
|
Veri Madenciliği Vize Deneme Sınavı -3
|
Veri Madenciliği Vize Deneme Sınavı -3
|


Yönetim Bilişim Sistemleri Lisans
Auzef Yönetim Bilişim Sistemleri Lisans 4. Sınıf Bahar Dönemi Vize Sınav Soruları ve Deneme Sınavları, 2024 Sınav Soruları