
Veri Madenciliği Final Deneme Sınavı -2
Veri Madenciliği Final Deneme Sınavı -2
#1. Katmanlı (stratified) örnekleme hangi durumda kullanılır?
Cevap: A) Tüm nesne tiplerini yeterince temsil etmeyen durumlarda
Açıklama: Katmanlı örnekleme, tüm nesne tiplerinin yeterince temsil edilmediği durumlarda kullanılır, böylece her bir kategoriye ait veri temsil edilir.
#2. kNN'nin sınırlamalarından biri nedir?
Cevap: C) Dengesiz sınıfların etkisi
Açıklama: kNN algoritmasının sınırlamalarından biri, dengesiz sınıfların etkisidir. Bu durumda, azınlık sınıflar yeterince temsil edilmez ve bu da sınıflandırma performansını olumsuz etkiler.
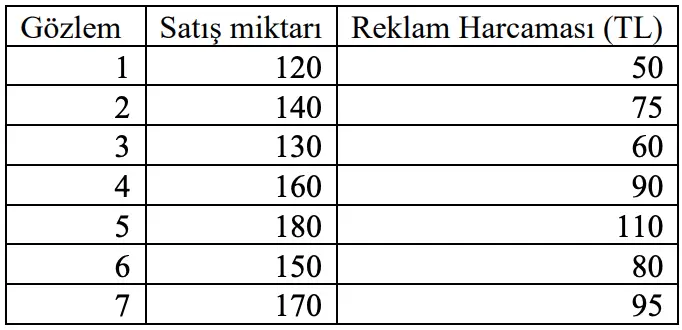
#3. Reklam için harcanan miktara bağlı olarak bir ürünün satışlarını tahmin etmek istediğimizi varsayalım. - 150 TL’lik reklam harcaması yapıldığı durumdaki tahmini satış miktarı ne kadar olur?
Cevap: E) 223
Açıklama: Regresyon denklemi Y = 66,86 1,04X olduğuna göre, Y = 66,86 1,04(150) = 223 olacaktır.
#4. Z-Skor Normalizasyonu nedir?
Cevap: D) Değerleri ortalaması 0 ve standart sapması 1 olacak şekilde dönüştürme
Açıklama: Z-skor normalizasyonu, verileri ortalaması 0 ve standart sapması 1 olacak şekilde dönüştürerek, farklı ölçeklerdeki verilerin karşılaştırılmasını kolaylaştırır.
#5. F1 skoru, neden hassasiyet ve duyarlılık metriklerinin harmonik ortalamasını kullanarak denge kurar?
Cevap: C) Hassasiyet ve duyarlılığın ortalamasını alarak dengeyi sağlar.
Açıklama: F1 skoru, hassasiyet (precision) ve duyarlılık (recall) metriklerinin harmonik ortalamasını alarak denge kurar ve bu sayede modelin genel performansını daha dengeli bir şekilde değerlendirir.
#6. Korelasyon katsayısı hangi durumda sıfıra eşit olur?
Cevap: C) Herhangi bir ilişki olmadığında
Açıklama: Korelasyon katsayısı, iki değişken arasında herhangi bir ilişki olmadığında sıfıra eşit olur.
#7. Metin madenciliği hangi adımda gürültüyü azaltarak veri kalitesini artırmayı amaçlar?
Cevap: D) Metin ön işleme
Açıklama: Metin ön işleme, metin madenciliği sürecinde gürültüyü azaltarak veri kalitesini artırmayı amaçlar. Bu adım, veriyi temizlemek ve analiz için hazırlamak için önemlidir.
#8. Kosinüs mesafesi genellikle hangi tür veri kümesinde kullanılır?
Cevap: B) Metin verileri
Açıklama: Kosinüs mesafesi, metin verileri arasında benzerlik ölçmek için yaygın olarak kullanılır ve vektörlerin arasındaki açıyı ölçerek benzerlik derecesini belirler.
#9. Sınıflandırma teknikleri genellikle hangi tür veri kümeleri üzerinde etkilidir?
Cevap: D) İki kategorili veriler
Açıklama: Sınıflandırma teknikleri, özellikle iki kategorili veriler üzerinde etkilidir, çünkü bu teknikler verileri belirli sınıflara ayırmayı amaçlar.
#10. Bir regresyon analizinde bağımsız değişkenin katsayısının 2,16 bulunması neyi ifade eder?
Cevap: B) Bağımsız değişkenin bağımlı değişken üzerindeki etkisinin bir birim artışla 2,16 birim arttığını gösterir.
Açıklama: Regresyon analizinde bağımsız değişkenin katsayısı, bağımsız değişkendeki bir birimlik artışın bağımlı değişkende ne kadar bir artışa neden olduğunu gösterir.
#11. Öznitelik ayrıklaştırması aşağıdakilerden hangisini içerir?
Cevap: B) Sürekli bir değişkenin kategorik bir değişkene dönüştürülmesi
Açıklama: Öznitelik ayrıklaştırması, sürekli bir değişkenin belirli aralıklara veya kategorilere dönüştürülmesini içerir.
#12. Reklam için harcanan miktara bağlı olarak bir ürünün satışlarını tahmin etmek istediğimizi varsayalım. - Sabit katsayı (a) kaçtır?
Cevap: D) 66,86
Açıklama: Regresyon denkleminin sabit katsayısı, modelin kesişim noktası olarak bulunur ve bu örnekte 66,86 olarak hesaplanmıştır.
#13. Sınıflandırma teknikleri hangi durumda daha az etkili olabilir?
Cevap: D) Sıralı kategoriler içeren veri setlerinde
Açıklama: Sınıflandırma teknikleri, sıralı kategoriler içeren veri setlerinde daha az etkili olabilir, çünkü bu tür veri setlerinde sınıflar arasındaki sıralama bilgisi önemlidir.
#14. Regresyon analizindeki eş varyanslık (homoscedasticity) kavramı ne anlama gelir?
Cevap: A) Hataların sabit bir varyansa sahip olduğunu
Açıklama: Homoscedasticity, hataların sabit bir varyansa sahip olduğu durumu ifade eder. Bu, regresyon analizinde önemli bir varsayımdır.
#15. Bir veri madenciliği analizi için ihtiyacımız olan tüm verileri toplamak ve işlemek için yeterli zamanımız olmadığında, örneklem büyüklüğü nasıl belirlenir?
Cevap: C) Uyarlanabilir örneklemeyle
Açıklama: Uyarlanabilir örnekleme, sınırlı zaman ve kaynaklarla veri toplama ve işleme işlemini optimize etmek için kullanılır.
#16. Hangi yaklaşım özniteliklerin, veri madenciliği algoritması çalıştırılmadan önce, veri madenciliği görevinden bağımsız bir şekilde seçilmesini benimser?
Cevap: A) Filtre yaklaşım
Açıklama: Filtre yaklaşım, özniteliklerin veri madenciliği görevinden bağımsız olarak seçilmesini benimser ve bu sayede daha genel ve esnek bir seçim süreci sağlar.
#17. Duygu analizi neyi amaçlar?
Cevap: B) Pozitif, negatif veya nötr duygusal kategorilere ayırmayı
Açıklama: Duygu analizi, metin verilerini pozitif, negatif veya nötr duygusal kategorilere ayırmayı amaçlar.
#18. Gizli anlam çözümlemesi (LSA) nedir?
Cevap: B) Bir metin kümesindeki ana fikirleri çıkarmak ve temsil etmek için kullanılan bir istatistiksel yöntemdir.
Açıklama: Gizli anlam çözümlemesi (LSA), bir metin kümesindeki ana fikirleri çıkarmak ve temsil etmek için kullanılan bir istatistiksel yöntemdir.
#19. Metin analitiği ile ilgili olarak aşağıdakilerden hangisi yanlıştır?
Cevap: D) Nominal veri türleriyle sınırlıdır.
Açıklama: Metin analitiği, yalnızca nominal veri türleriyle sınırlı değildir; yapılandırılmamış metinsel veriyi anlamak ve bilgi çıkarmak için çeşitli veri türlerini kullanır.
#20. Metin madenciliği ile ilgili olarak hangisi yanlıştır?
Cevap: D) Doğal dil işlemede yapılanları kapsar.
Açıklama: Metin madenciliği, yapılandırılmamış metin verilerini analiz etmek ve bu verilerden anlamlı bilgileri çıkarmak için kullanılan bir tekniktir. Metin madenciliği adımları arasında metnin belirli parçalara bölünmesi (tokenizasyon), metin verilerinin sayısal formata dönüştürülmesi için özellikler eklenmesi (özellik mühendisliği) ve model oluşturma gibi işlemler yer alır. Doğal dil işleme (NLP) ise, metin madenciliğinin önemli bir bileşeni olarak kabul edilmekle birlikte, metin madenciliği doğrudan NLP’de yapılan tüm işlemleri kapsamaz. Bu nedenle, “Doğal dil işlemede yapılanları kapsar” ifadesi yanlıştır. Metin madenciliği, metin verilerini anlamak için özel teknikleri içerir ve bu teknikler, doğal dil işlemenin ötesine geçerek metin verilerinden anlamlı bilgileri çıkarmaya odaklanır
SONUÇ
İstanbul Üniversitesi Açık ve Uzaktan Eğitim Fakültesi (Auzef)
Açık Öğretim Fakültesi
Bölüm : Yönetim Bilişim Sistemleri Lisans
4. Sınıf Veri Madenciliği Bahar Dönemi
Veri Madenciliği Final Deneme Sınavı -2
İstanbul Üniversitesi Açık ve Uzaktan Eğitim Fakültesi (Auzef)
Açık Öğretim Fakültesi
Bölüm : Yönetim Bilişim Sistemleri Lisans
4. Sınıf Veri Madenciliği Bahar Dönemi
Veri Madenciliği Final Deneme Sınavı -2



HD Quiz powered by harmonic design
Veri Madenciliği Final Deneme Sınavı -2
| İstanbul Üniversitesi Açık ve Uzaktan Eğitim Fakültesi (Auzef) Açık Öğretim Fakültesi Bölüm : Yönetim Bilişim Sistemleri Lisans 4. Sınıf Veri Madenciliği Bahar Dönemi Veri Madenciliği Final Deneme Sınavı -2 |
|---|
Veri Madenciliği Final Deneme Sınavı -2
|
Veri Madenciliği Final Deneme Sınavı -2
|
|


Veri Madenciliği Final Deneme Sınavı -2
Yönetim Bilişim Sistemleri Lisans
Auzef Yönetim Bilişim Sistemleri Lisans 4. Sınıf Bahar Dönemi Final Sınav Soruları ve Deneme Sınavları, 2024 Sınav Soruları
